Syscalls and resources restriction
Syscalls restriction
What are syscalls ?
When an application crashes because of a bug, the problem has to be contained in such a way that the underlying operating system is not affected.
Imagine if your Tetris game is crashing while saving your highscore. Because it didn’t finish its operations on the disk, it can corrupt it, or leave it in such a state that would cause troubles for any other application to use it afterward.
One funny example of that principle was demonstrated live with the very famous Windows 98 live fail, which is also why nowadays live demonstrations are replaced with pre-recorded demos
To avoid this case to happend, Linux separates software into 2 “lands”, kernel-land and user-land.
The kernel-land is priviliged, meaning it owns every bit of the machine (to some exceptions like the processor-level context separation of Arm TrustZone), it can read and write into all the memory and uses drivers to interact with the connected peripherals.
The user-land is un-priviliged, meaning that even an almighty root account do not have full-control on the machine directly, but this level of power allows to perform any kind of syscalls.
Syscalls are the way a user-land application can perform an action that is normally done by the kernel.
Syscalls are a special assembly machine code, each syscall has an “index” that is passed to a register, when executing the
syscallcommand, it will switch into the kernel code responsible for handling such a syscall.
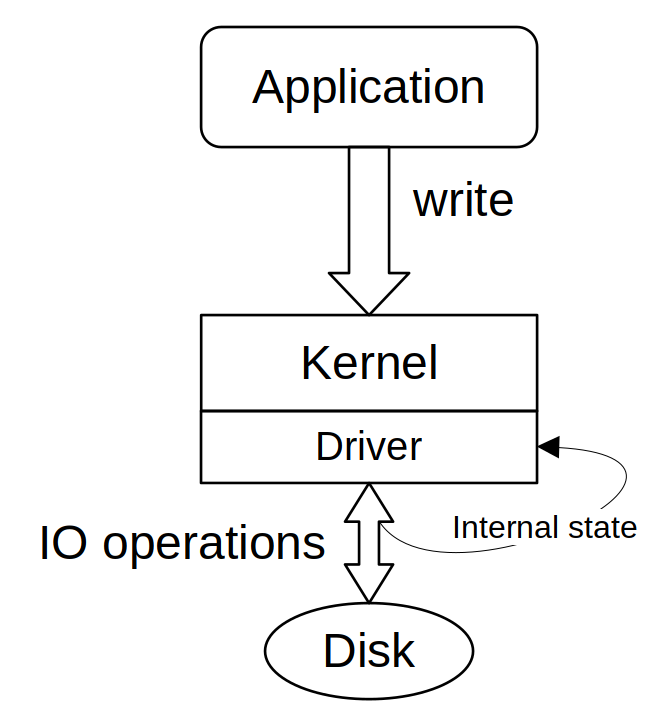
Here is a representation of an application writing to the disk using the write syscall.
When using
writein another langage like Python, it usually calls thewritefunction of C as this function is directly translated into the corresponding syscall when compiled.
The driver is embedded in the kernel as a module, and it manages its internal state and operations internally. This way if anything goes wrong and another application wants to write, it can reset its state, take care of the special operations that the underlying physical device requires (I’m looking at you, eMMC !)
More on the linux kernel drivers in this article (BEWARE OF THE ARTICLE COLORS, protect your eyes, seriously).
A complete list of all the syscalls that can be called with a Linux kernel is available here
Seccomp and syscalls restriction
As syscalls allows a user to control the system, it is necessary to restrict any syscall that may allow a procssed inside our container to harm our underlying operating system.
Enters Seccomp
As given by the wikipedia page of seccomp:
seccomp (short for secure computing mode) is a computer security facility in the Linux kernel.
seccomp allows a process to make a one-way transition into a “secure” state where it cannot make any system calls exceptexit(),sigreturn(),read()andwrite()to already-open file descriptors. Should it attempt any other system calls, the kernel will terminate the process with SIGKILL or SIGSYS. In this sense, it does not virtualize the system’s resources but isolates the process from them entirely.
seccomp mode is enabled via the prctl(2) system call using the PR_SET_SECCOMP argument, or (since Linux kernel 3.17) via the seccomp(2) system call.
It’s kinda easy to see how seccomp is one of the backbone for a container such as Docker, basically it isolates a process into a state where it can only read and write into the filesystem, or exit.
This secore computing mode is very restrtictive by default as it denies any syscall attempt. However for the good functionnality of our container, we may want to configure this and add exceptions.
To do this, we can set a profile for seccomp, which defines special rules, allows some syscalls, or triggers special actions.
For our container, we will configure seccomp to allow all syscalls by default then refuse some using our profile.
What syscalls to restrict ?
In this tutorial we won’t look closely at each syscall we will refuse / allow as deep descriptions with some examples of exploits are given in the “syscalls” section of the original tutorial.
Also, as pointed out in the original tutorial, good sources for syscalls restrictions are the docker documentation page and the seccomp profile of moby.
The syscalls we will refuse in our container are:
// Kernel keyring
keyctl
add_key
request_key
// NUMA (memory management)
mbind
migrate_pages
move_pages
set_mempolicy
// Allow userland to handle memory faults in the kernel
userfaultfd
// Trace / profile syscalls
perf_event_open
Some additionnal resources about what we restrict:
Kernel keyring
NUMA
Userland memory handling
Syscalls tracing
Applying seccomp
To set this seccomp restriction on our child process, we will use the crate syscallz, and will also require libc. \ In Cargo.toml add:
[dependencies]
# ...
syscallz = "0.16.1"
libc = "0.2.102"
Let’s create a file src/syscalls.rs and create a function like so:
use syscallz::{Context, Action};
pub fn setsyscalls() -> Result<(), Errcode> {
log::debug!("Refusing / Filtering unwanted syscalls");
// Unconditionnal syscall deny
// Conditionnal syscall deny
// Initialize seccomp profile with all syscalls allowed by default
if let Ok(mut ctx) = Context::init_with_action(Action::Allow) {
// Configure profile here
if let Err(_) = ctx.load(){
return Err(Errcode::SyscallsError(0));
}
Ok(())
} else {
Err(Errcode::SyscallsError(1))
}
}
Of course, let’s pipe everything in our crate so this can work, and let’s call this function inside the child configuration function.
In src/main.rs:
// ...
mod syscalls;
In src/errors.rs:
pub enum Errcode {
// ...
SyscallsError(u8),
}
In src/child.rs:
use crate::syscalls::setsyscalls;
pub fn setup_container_configurations(config: &ContainerOpts) -> Result<(), Errcode> {
// ...
setsyscalls()?;
Ok(())
}
Unconditionnal syscalls restriction
Let’s first refuse the syscalls we don’t want the child to execute.
For this, we create the function refuse_syscall to totally deny any attempt to call that syscall in the child process.
const EPERM: u16 = 1;
fn refuse_syscall(ctx: &mut Context, sc: &Syscall) -> Result<(), Errcode>{
match ctx.set_action_for_syscall(Action::Errno(EPERM), *sc){
Ok(_) => Ok(()),
Err(_) => Err(Errcode::SyscallsError(2)),
}
}
We then list the syscalls we want to refuse, and iter through them to populate the profile.
use crate::syscallz::Syscall;
pub fn setsyscalls() -> Result<(), Errcode> {
// ...
// Unconditionnal syscall deny
let syscalls_refused = [
Syscall::keyctl,
Syscall::add_key,
Syscall::request_key,
Syscall::mbind,
Syscall::migrate_pages,
Syscall::move_pages,
Syscall::set_mempolicy,
Syscall::userfaultfd,
Syscall::perf_event_open,
];
if let Ok(mut ctx) = Context::init_with_action(Action::Allow){
// ...
for sc in syscalls_refused.iter() {
refuse_syscall(&mut ctx, sc)?;
}
// ...
}
}
Conditionnal syscalls restriction
Syscalls can be restricted when a particular condition is met.
For this, we create a rule that takes a value and return wether the permission should be set or not. As we have a basic usage of this functionnality, we simply test wether the variable is equal or not to an expected value.
Let’s create the refuse_if_comp function implementing this:
use syscallz::{Comparator, Cmp};
fn refuse_if_comp(ctx: &mut Context, ind: u32, sc: &Syscall, biteq: u64)-> Result<(), Errcode>{
match ctx.set_rule_for_syscall(Action::Errno(EPERM), *sc,
&[Comparator::new(ind, Cmp::MaskedEq, biteq, Some(biteq))]){
Ok(_) => Ok(()),
Err(_) => Err(Errcode::SyscallsError(3)),
}
}
What this Comparator will do is to take the argument number ind passed to the syscall, and compare it using the mask biteq to the value biteq.
This is equivalent to testing if the bit biteq is set.
Let’s add all the rules we want to set for our syscalls:
use libc::TIOCSTI;
use nix::sys::stat::Mode;
use nix::sched::CloneFlags;
pub fn setsyscalls() -> Result<(), Errcode> {
// ...
let s_isuid: u64 = Mode::S_ISUID.bits().into();
let s_isgid: u64 = Mode::S_ISGID.bits().into();
let clone_new_user: u64 = CloneFlags::CLONE_NEWUSER.bits() as u64;
// Conditionnal syscall deny
let syscalls_refuse_ifcomp = [
(Syscall::chmod, 1, s_isuid),
(Syscall::chmod, 1, s_isgid),
(Syscall::fchmod, 1, s_isuid),
(Syscall::fchmod, 1, s_isgid),
(Syscall::fchmodat, 2, s_isuid),
(Syscall::fchmodat, 2, s_isgid),
(Syscall::unshare, 0, clone_new_user),
(Syscall::clone, 0, clone_new_user),
(Syscall::ioctl, 1, TIOCSTI),
];
if let Ok(mut ctx) = Context::init_with_action(Action::Allow){
// ...
for (sc, ind, biteq) in syscalls_refuse_ifcomp.iter(){
refuse_if_comp(&mut ctx, *ind, sc, *biteq)?;
}
// ...
}
}
Testing
Everything is now set ! Let’s test this out:
[2022-03-09T09:08:27Z INFO crabcan] Args { debug: true, command: "/bin/bash", uid: 0, mount_dir: "./mountdir/" }
[2022-03-09T09:08:27Z DEBUG crabcan::container] Linux release: 5.13.0-30-generic
[2022-03-09T09:08:27Z DEBUG crabcan::container] Container sockets: (3, 4)
[2022-03-09T09:08:27Z DEBUG crabcan::hostname] Container hostname is now soft-world-116
[2022-03-09T09:08:27Z DEBUG crabcan::mounts] Setting mount points ...
[2022-03-09T09:08:27Z DEBUG crabcan::mounts] Mounting temp directory /tmp/crabcan.Qo04pP4PBG9U
[2022-03-09T09:08:27Z DEBUG crabcan::mounts] Pivoting root
[2022-03-09T09:08:27Z DEBUG crabcan::mounts] Unmounting old root
[2022-03-09T09:08:27Z DEBUG crabcan::namespaces] Setting up user namespace with UID 0
[2022-03-09T09:08:27Z DEBUG crabcan::namespaces] Child UID/GID map done, sending signal to child to continue...
[2022-03-09T09:08:27Z DEBUG crabcan::container] Creation finished
[2022-03-09T09:08:27Z DEBUG crabcan::container] Container child PID: Some(Pid(130688))
[2022-03-09T09:08:27Z DEBUG crabcan::container] Waiting for child (pid 130688) to finish
[2022-03-09T09:08:27Z INFO crabcan::namespaces] User namespaces set up
[2022-03-09T09:08:27Z DEBUG crabcan::namespaces] Switching to uid 0 / gid 0...
[2022-03-09T09:08:27Z DEBUG crabcan::capabilities] Clearing unwanted capabilities ...
[2022-03-09T09:08:27Z DEBUG crabcan::syscalls] Refusing / Filtering unwanted syscalls
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=chmod comparators=[Comparator { arg: 1, op: MaskedEq, datum_a: 2048, datum_b: 2048 }]
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=chmod comparators=[Comparator { arg: 1, op: MaskedEq, datum_a: 1024, datum_b: 1024 }]
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=fchmod comparators=[Comparator { arg: 1, op: MaskedEq, datum_a: 2048, datum_b: 2048 }]
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=fchmod comparators=[Comparator { arg: 1, op: MaskedEq, datum_a: 1024, datum_b: 1024 }]
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=fchmodat comparators=[Comparator { arg: 2, op: MaskedEq, datum_a: 2048, datum_b: 2048 }]
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=fchmodat comparators=[Comparator { arg: 2, op: MaskedEq, datum_a: 1024, datum_b: 1024 }]
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=unshare comparators=[Comparator { arg: 0, op: MaskedEq, datum_a: 268435456, datum_b: 268435456 }]
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=clone comparators=[Comparator { arg: 0, op: MaskedEq, datum_a: 268435456, datum_b: 268435456 }]
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=ioctl comparators=[Comparator { arg: 1, op: MaskedEq, datum_a: 21522, datum_b: 21522 }]
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=keyctl
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=add_key
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=request_key
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=mbind
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=migrate_pages
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=move_pages
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=set_mempolicy
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=userfaultfd
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=perf_event_open
[2022-03-09T09:08:27Z DEBUG syscallz] seccomp: loading policy
[2022-03-09T09:08:27Z INFO crabcan::child] Container set up successfully
[2022-03-09T09:08:27Z INFO crabcan::child] Starting container with command /bin/bash and args ["/bin/bash"]
[2022-03-09T09:08:27Z DEBUG crabcan::container] Finished, cleaning & exit
[2022-03-09T09:08:27Z DEBUG crabcan::container] Cleaning container
[2022-03-09T09:08:27Z DEBUG crabcan::errors] Exit without any error, returning 0
It generates a bit of logging as the crate syscallz is set to use log as well as our project.
However it shows very well that our syscalls are now filtered, and we can get to the next step !
Patch for this step
The code for this step is available on github litchipi/crabcan branch “step13”.
The raw patch to apply on the previous step can be found here
Resources restriction
Cgroups
Cgroups is a mechanism introduced in Linux v2.6.4 which allows to “allocate” ressources for a group of processes.
For the given group of processes, the system will “look like” it only has X of a given resource.
This amount cannot be superior than what your system initially has, it is not a virtualization feature, but a restriction feature.
In a Linux system, you can use /sys/fs/cgroup/ to set limits to a process by doing so:
# 100 Mib
echo 100000000 > /sys/fs/cgroup/memory/<groupname>/memory.limit_in_bytes
As this feature has been reworked, two versions coexist in the Linux kernel.
The main difference for us users is that the v2 groups all the configuration for a given group under the same directory.
For more information about them, you can check this great serie of articles on LWN.
This feature is used a lot in the containerisation of applications on a same server, and to be able to sell a specific set of performances on a server to a customer, then upgrade it whenever he purchases a performance boost.
This feature is so crucial to containers that a recent vulnerability let attackers escape from the container and infect the host system directly. You have to remember that as we give full power to the contained application, if this app manages to escape the box, it may keep its powers on the host system
Limitting the CPU time
To limit the CPU, cgroup uses weights to determine how much CPU time a process will get.
By default cgroup will grant a process a weight of 1024, but this weight can go from 1 to 2^64.
The more the weight compared to the others, the more CPU shares.
If 3 processes have a weight of 25000, they will all have the same CPU time than if they all have 1024. The great range of values allows for fine tuning of this value.
More informations on CPU sharing can be found on this article of redhat
Rlimit
Rlimit is a system used to restrict a single process.
It’s focus is more centered around what this process can do than what realtime system ressources it consumes.
For details on rlimit you can check this great article from which I extracted the list of all the rlimits available:
RLIMIT_CPU CPU time limit given in seconds
RLIMIT_FSIZE the maximum size of files that a process may create
RLIMIT_DATA the maximum size of the process's data segment
RLIMIT_STACK the maximum size of the process stack in bytes
RLIMIT_CORE the maximum size of a core file.
RLIMIT_RSS the number of bytes that can be allocated for a process in RAM
RLIMIT_NPROC the maximum number of processes that can be created by a user
RLIMIT_NOFILE the maximum number of a file descriptor that can be opened by a process
RLIMIT_MEMLOCK the maximum number of bytes of memory that may be locked into RAM by mlock.
RLIMIT_AS the maximum size of virtual memory in bytes.
RLIMIT_LOCKS the maximum number flock and locking related fcntl calls
RLIMIT_SIGPENDING maximum number of signals that may be queued for a user of the calling process
RLIMIT_MSGQUE the number of bytes that can be allocated for POSIX message queues
RLIMIT_NICE the maximum nice value that can be set by a process
RLIMIT_RTPRIO maximum real-time priority value
RLIMIT_RTTIME maximum number of microseconds that a process may be scheduled under real-time scheduling policy without making blocking system call
We will use rlimit to limit the number of file descriptor the process can open, because, as stated in the original tutorial:
The file descriptor number, like the number of pids, is per-user, and so we want to prevent in-container process from occupying all of them.
So we need to set the RLIMIT_NOFILE
It is theorically possible that rlimit and cgroups “overlap” their restrictions (the first limit reached will be the limiting one), but in practice their application area is different and that should almost never happend.
Note that as rlimit uses a syscall, these settings can be re-configured from a process, which is why we added the CAP_SYS_RESOURCE to the blacklist of syscalls the contained process can make.
Restricting the resources
There’s a create call cgroups_rs that will ease everything related to the cgroups definition, but remember that as everything in Unix is a file (and Linux follows the philosophy of Unix), even if we didn’t have this crate, we would only have to write into the correct file.
We will also use the crate rlimit which wraps the call to the system call we need.
In a new file src/resources.rs, let’s create a function to restrict the resources inside our container.
use rlimit::{setrlimit, Resource};
use cgroups_rs::cgroup_builder::CgroupBuilder;
// KiB MiB Gib
const KMEM_LIMIT: i64 = 1024 * 1024 * 1024;
const MEM_LIMIT: i64 = KMEM_LIMIT;
const MAX_PID: MaxValue = MaxValue::Value(64);
const NOFILE_RLIMIT: u64 = 64;
pub fn restrict_resources(hostname: &String) -> Result<(), Errcode>{
log::debug!("Restricting resources for hostname {}", hostname);
// Cgroups
let cgs = CgroupBuilder::new(hostname)
// Allocate less CPU time than other processes
.cpu().shares(256).done()
// Limiting the memory usage to 1 GiB
// The user can limit it to less than this, never increase above 1Gib
.memory().kernel_memory_limit(KMEM_LIMIT).memory_hard_limit(MEM_LIMIT).done()
// This process can only create a maximum of 64 child processes
.pid().maximum_number_of_processes(MAX_PID).done()
// Give an access priority to block IO lower than the system
.blkio().weight(50).done()
.build(Box::new(V2::new()));
// We apply the cgroups rules to the child process we just created
let pid : u64 = pid.as_raw().try_into().unwrap();
if let Err(_) = cgs.add_task(CgroupPid::from(pid)) {
return Err(Errcode::ResourcesError(0));
};
// Rlimit
// Can create only 64 file descriptors
if let Err(_) = setrlimit(Resource::NOFILE, NOFILE_RLIMIT, NOFILE_RLIMIT){
return Err(Errcode::ResourcesError(0));
}
Ok(())
}
We can use this fresh function inside the create function of our container, as it only requires the hostname to apply the restriction.
use crate::resources::restrict_resources;
impl Container {
// ...
pub fn create(&mut self) -> Result<(), Errcode> {
let pid = generate_child_process(self.config.clone())?;
restrict_resources(&self.config.hostname, pid)?;
// ...
}
}
Let’s add the required dependencies in Cargo.toml:
[dependencies]
# ...
cgroups-rs = "0.2.6"
rlimit = "0.6.2"
We also need to add this new module inside src/main.rs:
// ...
mod resources;
And the new error variant in src/errors.rs:
pub enum Errcode {
// ...
ResourcesError(u8),
}
Cleaning the restrictions
After the child process exited, we need to clean all the cgroups restriction we added.
This is very simple as cgroups v2 centralises everything in a directory under /sys/fs/cgroup/<groupname>/, so we just delete it.
In src/resources.rs:
pub fn clean_cgroups(hostname: &String) -> Result<(), Errcode>{
log::debug!("Cleaning cgroups");
match canonicalize(format!("/sys/fs/cgroup/{}/", hostname)){
Ok(d) => {
if let Err(_) = remove_dir(d) {
return Err(Errcode::ResourcesError(2));
}
},
Err(e) => {
log::error!("Error while canonicalize path: {}", e);
return Err(Errcode::ResourcesError(3));
}
}
Ok(())
}
This function will be called inside the clean_exit function of the file src/container.rs:
use crate::resources::clean_cgroups;
impl Container {
// ...
pub fn clean_exit(&mut self) -> Result<(), Errcode> {
// ...
if let Err(e) = clean_cgroups(&self.config.hostname){
log::error!("Cgroups cleaning failed: {}", e);
return Err(e);
}
Ok(())
}
}
Testing
[2022-03-09T13:58:37Z INFO crabcan] Args { debug: true, command: "/bin/bash", uid: 0, mount_dir: "./mountdir/" }
[2022-03-09T13:58:37Z DEBUG crabcan::container] Linux release: 5.13.0-30-generic
[2022-03-09T13:58:37Z DEBUG crabcan::container] Container sockets: (3, 4)
[2022-03-09T13:58:37Z DEBUG crabcan::resources] Restricting resources for hostname small-girl-247
[2022-03-09T13:58:37Z DEBUG crabcan::hostname] Container hostname is now small-girl-247
[2022-03-09T13:58:37Z DEBUG crabcan::mounts] Setting mount points ...
[2022-03-09T13:58:37Z DEBUG crabcan::mounts] Mounting temp directory /tmp/crabcan.LH9HSKzfsmN7
[2022-03-09T13:58:37Z DEBUG crabcan::mounts] Pivoting root
[2022-03-09T13:58:37Z DEBUG crabcan::mounts] Unmounting old root
[2022-03-09T13:58:37Z DEBUG crabcan::namespaces] Setting up user namespace with UID 0
[2022-03-09T13:58:37Z DEBUG crabcan::namespaces] Child UID/GID map done, sending signal to child to continue...
[2022-03-09T13:58:37Z DEBUG crabcan::container] Creation finished
[2022-03-09T13:58:37Z DEBUG crabcan::container] Container child PID: Some(Pid(162889))
[2022-03-09T13:58:37Z DEBUG crabcan::container] Waiting for child (pid 162889) to finish
[2022-03-09T13:58:37Z INFO crabcan::namespaces] User namespaces set up
[2022-03-09T13:58:37Z DEBUG crabcan::namespaces] Switching to uid 0 / gid 0...
[2022-03-09T13:58:37Z DEBUG crabcan::capabilities] Clearing unwanted capabilities ...
[2022-03-09T13:58:37Z DEBUG crabcan::syscalls] Refusing / Filtering unwanted syscalls
[2022-03-09T13:58:37Z DEBUG syscallz] seccomp: setting action=Errno(1) syscall=chmod comparators=[Comparator { arg: 1, op: MaskedEq, datum_a: 2048, datum_b: 2048 }]
...
[2022-03-09T13:58:37Z DEBUG syscallz] seccomp: loading policy
[2022-03-09T13:58:37Z INFO crabcan::child] Container set up successfully
[2022-03-09T13:58:37Z INFO crabcan::child] Starting container with command /bin/bash and args ["/bin/bash"]
[2022-03-09T13:58:37Z DEBUG crabcan::container] Finished, cleaning & exit
[2022-03-09T13:58:37Z DEBUG crabcan::container] Cleaning container
[2022-03-09T13:58:37Z DEBUG crabcan::resources] Cleaning cgroups
[2022-03-09T13:58:37Z DEBUG crabcan::errors] Exit without any error, returning 0
Patch for this step
The code for this step is available on github litchipi/crabcan branch “step14”.
The raw patch to apply on the previous step can be found here
Precedent post in this serie: User namespaces and Linux Capabilties
Next post in this serie: Executing the binary